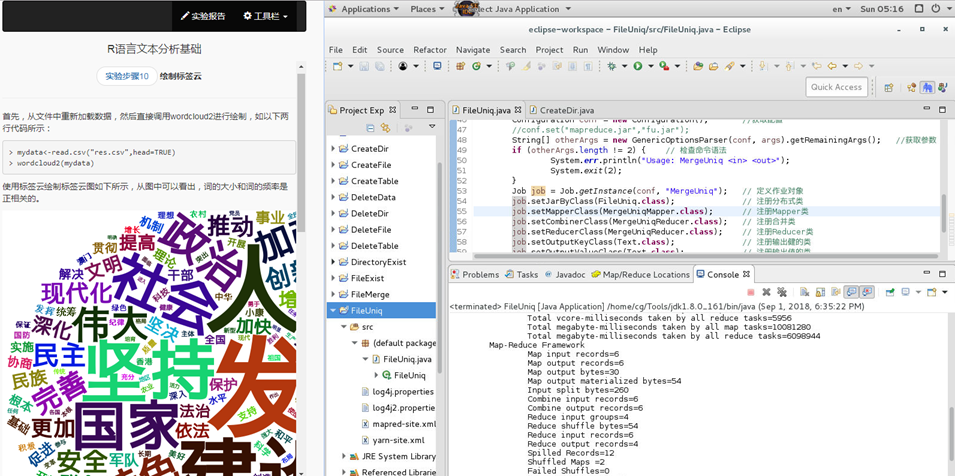
在线虚拟实验环境
学生直接在浏览器上进行实验,界面分为左右两栏,左栏为实验指导书,右侧为一个真实的虚拟机环境。学习者无需配置繁琐的本地环境,随时随地在线流畅使用,极佳的用户体验。
借助虚拟机管理平台实现多节点实验服务器快速部署,节约学生安装实验环境花费的时间,随时随地在线流畅使用。实验后能够长期保存学生实验过程资料。
支持任何虚拟化技术,可以充分利用学校现有的计算中心(云计算中心)物理设备,为学校打造计算机实验在线机房。
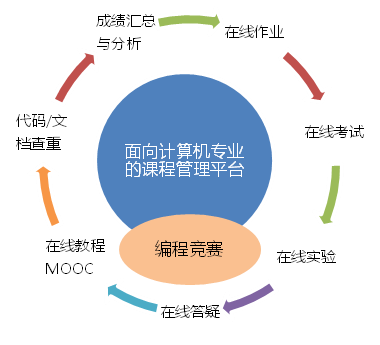
大数据专业一体化支撑平台
- 完善的课程管理与考试平台
-
支撑整个大数据专业的教学过程,实现在线资源的统一管理。
支持各类题型(填空、选择、判断、文件上传、简答、编程等)、在线作业、在线实验、在线考试、在线答疑等课程管理功能,支持MOOC视频播放。
- 代码自动评判
-
利用代码自动评判功能支持大数据基础课程(Python、Java等)编程语言教学。 深入了解 。
- 教育大数据沉淀
-
CG平台完整汇集学生在整个培养阶段的学习过程数据、项目实践数据、考试成绩数据,沉淀自己学校专属的大数据。
CG大数据解决方案特色
一门课仅需一台服务器。基于虚拟机多用户共享,和Hadoop集群共享计算环境,极大节约计算资源,一台服务器支撑300人同时在线实验。
| CG大数据 | 其它 | |
|---|---|---|
| 软件平台与硬件松耦合 |
独立建设、独立维护升级换代 |
一体机模式,与服务器和虚拟化软件紧耦合 |
| 对专业支撑的全面性 |
支撑所有大数据专业课程的教学与实验 |
昂贵的软硬件,只能做有限的大数据实验,无法支持相关课程的实验,例如数据库、编程语言、操作系统等 |
| 资源的可扩展性 |
轻松自建教学与实验资源 |
教学与实验资源固化 |
| 使用体验 |
B/S架构图形桌面,客户端分辨率自适应 |
C/S架构或者命令行界面 |
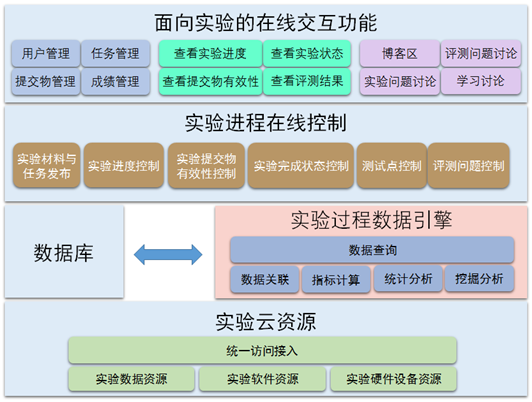 基于云计算技术,实验所需数据、软件共建和硬件实验设备均抽象为实验资源,提高了软硬件资源利用率,并利于系统维护和升级换代。
基于云计算技术,实验所需数据、软件共建和硬件实验设备均抽象为实验资源,提高了软硬件资源利用率,并利于系统维护和升级换代。
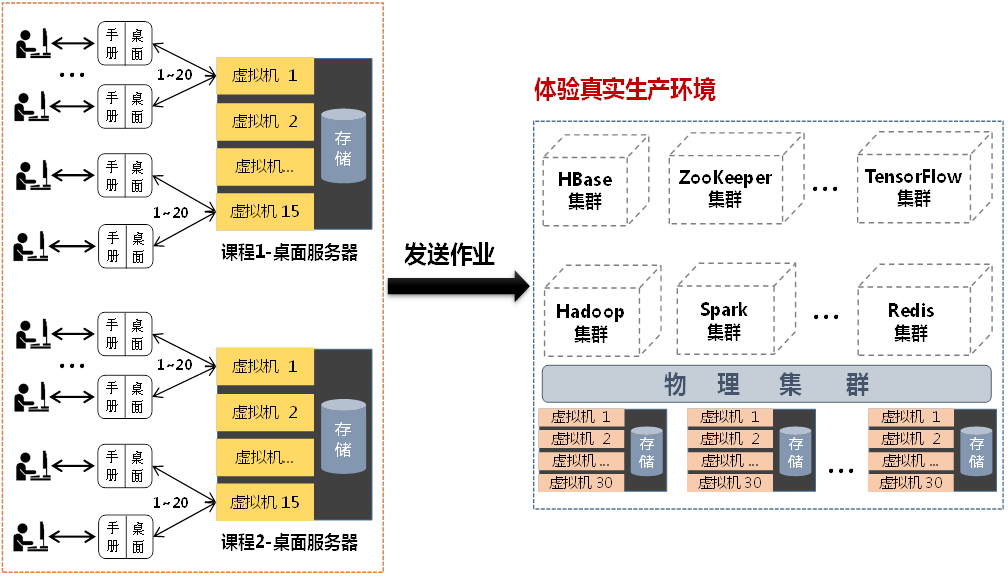
工业生产级实验环境架构
传统的人工智能与大数据的实验模式是给每个学生分配1台虚拟机,在虚拟机内预装人工智能和大数据的实验工具。受限于单台虚拟机的存储能力和计算能力,每个学生只能进行简单的“伪大数据”实验。
- CG实验架构具有以下几方面优势
-
大幅减少服务器数量。采用桌面和作业分离的架构,可大幅降低对硬件服务器资源的要求。在CG的工业生产级实验架构中,即每台服务器可支撑300人同时进行基于虚拟桌面的在线实验。CG大数据是目前唯一能够做到单台服务器支持300人并发的虚拟桌面在线实验环境。
体会大数据工具真正的魅力。事实上,如果集群的规模不够大,大数据工具的处理性能比单机上由C语言实现的具有同样功能的程序的性能还要差很多。只有作业集群的规模足够大时,学生才会体会到大数据工具在编程模型、弹性调度、水平扩展、运行时容错、高可靠设计等方面的魅力。
支撑学生开展大型实验。工业生产级集群为每个学生提供了更强大的存储能力和计算能力,为学生开展大型人工智能和大数据实训项目提供了基本条件。
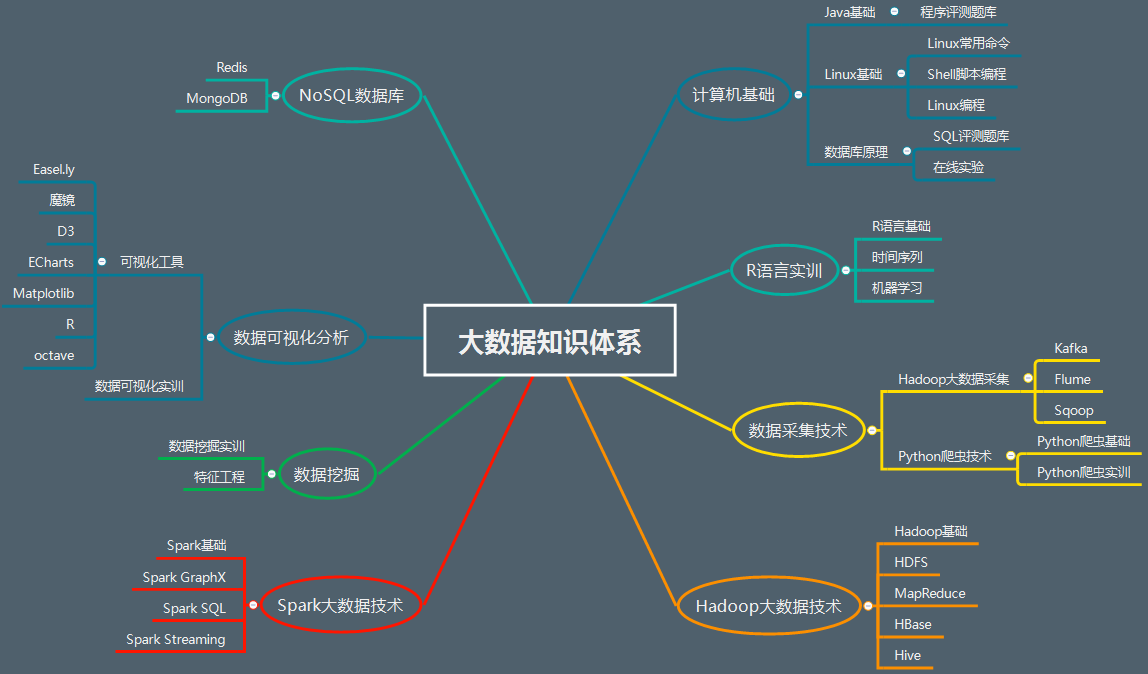
高质量的教学资源
大数据课程体系内相关课程: Python实训 Java程序设计 关系数据库实验 操作系统 算法与数据结构
大数据课程实验资源:Hadoop大数据开发、Spark大数据开发、NoSQL数据库、机器学习、数据采集技术、数据可视化分析、数据挖掘、R语言实训